The Revolutionary Future: Why Multimodal Generative AI is No Longer Just a Chatbot
The technological landscape is changing fast. For years, Artificial Intelligence (AI) was defined by text chatbots and basic image filters. Multimodal Generative AI has now fundamentally shifted this paradigm. This powerful technology moves beyond single data types. It understands and creates content using text, images, video, and audio simultaneously. This represents a monumental leap forward for students and working professionals worldwide.
- This revolutionary capability mirrors human perception.
- It is redefining how we interact with digital systems.
- The age of siloed text-only AI is quickly ending.
The ability to process and fuse different data streams is crucial. It unlocks a new dimension of creativity and efficiency. The shift from unimodal to Multimodal Generative AI is a necessary evolution. It drives us toward more intelligent, context-aware, and impactful applications.

The Revolutionary Shift to Multimodality
Generative AI started with remarkable but limited tools. Think of early text generators or simple image-from-prompt models. These systems were unimodal, meaning they operated on one data type. A language model handled text. A computer vision model processed only images.
Use OpenAI ChatGPT Free India: 1 Year of Unstoppable AI Sparks a Digital Revolution
Defining Cross-Modal Learning
Cross-modal learning is the core principle of Multimodal Generative AI. It involves training AI models to draw connections between different data types. For instance, the model learns the relationship between the written word “ocean,” the sound of waves, and a visual image of a blue sea.
- This integration creates a holistic understanding.
- It allows the AI to respond to a visual query with a descriptive text.
- Furthermore, it can generate corresponding audio for a video input.
This is fundamentally how humans learn and perceive. We constantly blend sensory inputs for context. Multimodal Generative AI replicates this advanced cognitive function.
The Limitations of Unimodal Systems
Unimodal systems, while powerful, quickly hit a complexity wall. A text-only model cannot accurately caption a nuanced photograph. An image model cannot grasp the emotional tone of an accompanying song.
In contrast, a Multimodal Generative AI can. It assesses all inputs together. Consequently, the output is richer, more accurate, and contextually relevant. This capability is vital for complex tasks. It ensures the AI understands the intent behind a mixed-media request. The future of problem-solving relies heavily on this cross-data coherence.
Beyond Text and Stills: The New Creative Frontier
The most immediate and captivating impact of this technology is in creative output. Creativity is no longer bound by a single medium. Multimodal Generative AI is empowering students and professionals to produce high-fidelity, complex media at unprecedented speed.
Automated Storytelling with generative video
Video content dominates online platforms and professional communication. Producing video has historically been time-consuming and costly. Generative video AI is changing this equation entirely
- It can create dynamic, movie-quality scenes from simple text prompts.
- Furthermore, it handles temporal consistency and object permanence.
- Working professionals in marketing and film production see massive gains.
Students can now prototype animated projects instantly. Marketers can generate dozens of ad variants in hours, not weeks. The ability to integrate text scripts, character descriptions, and scene directions into a cohesive generative video output is a game-changer for creative automation.
Synthesizing the Sonic Landscape: AI music creation
Music and audio are integral to emotional and professional communication. AI music creation tools, powered by multimodal principles, are democratizing sound design. These systems can synthesize original compositions that match a requested mood or tempo.
In addition, the AI can analyze a video clip or an image and automatically generate a perfectly synchronized, royalty-free soundtrack. This ability to link visual (video) and auditory (music) modalities via a textual prompt exemplifies true Multimodal Generative AI.
The Impact of Multimodal Generative AI on Professional Workflow
The real value of this technology for working professionals lies in its ability to streamline complex, multi-layered tasks. It shifts the focus from manual execution to strategic oversight. This results in significant productivity boosts across various industries.
Transforming Design and Prototyping: 3D model generation
Engineers, architects, and product designers spend countless hours on initial prototyping. The emergence of 3D model generation from text, images, or sketches dramatically compresses this timeline.
A designer can upload a hand-drawn concept and a text description. The Multimodal Generative AI synthesizes a textured, ready-to-refine 3D asset. This is a vital acceleration tool. It fundamentally changes the design lifecycle. 3D model generation allows for rapid iteration and testing.
We must recognize that this advancement demands new skills. Professionals must learn to prompt and curate, rather than manually model. This shift is explored in detail in our guide on specific anchor text: the future of AI agents and automation.

Engineering Efficiency: Real-Time Multimodal Analysis
Many high-stakes professional fields rely on fusing disparate data. Autonomous vehicles combine visual (cameras), range (LiDAR), and positional (GPS) data for real-time decision-making.
Furthermore, in finance, Multimodal Generative AI analyzes textual market reports alongside visual stock charts and emotional cues from trading floor audio. This comprehensive analysis leads to superior predictive accuracy and robust risk management strategies. This is a critical area where unimodal systems fail. The ability to correlate diverse data streams is paramount for engineering efficiency and reducing critical errors.
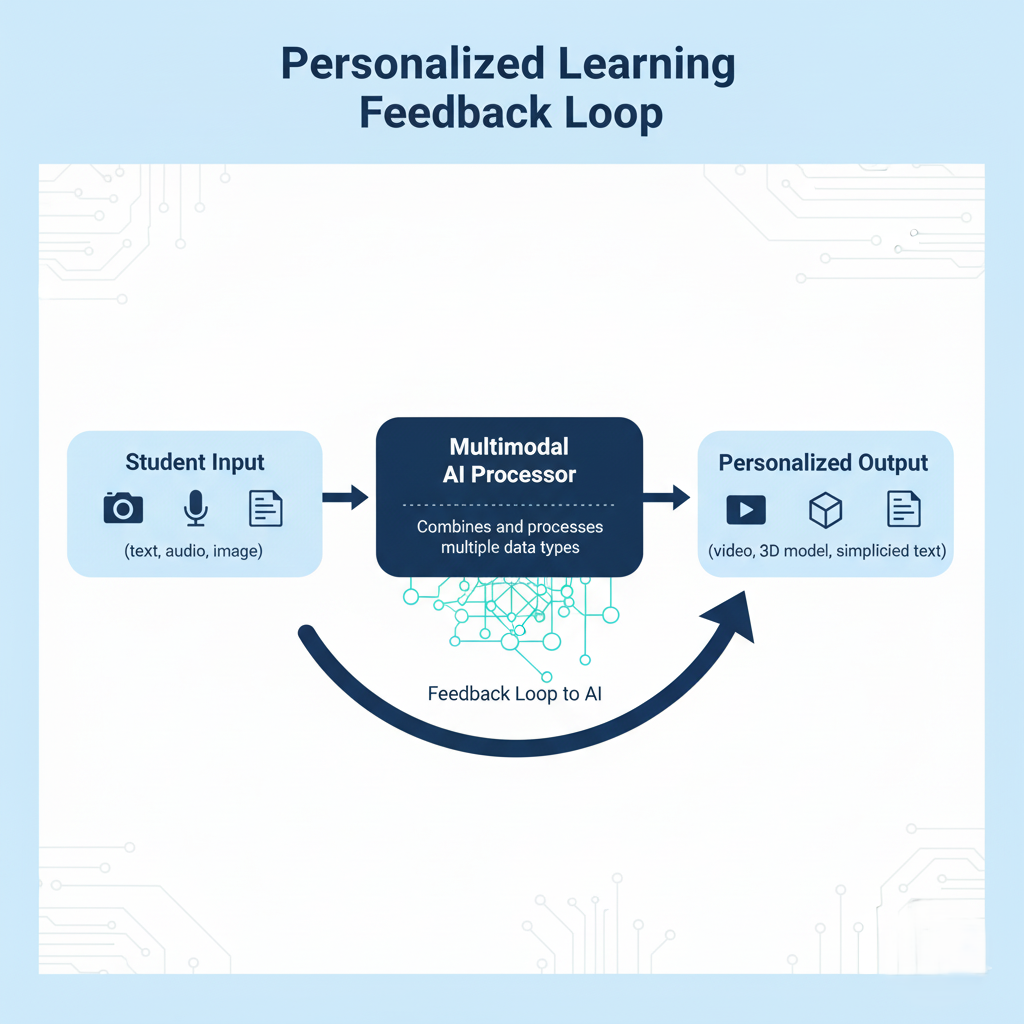
Education, Research, and the personalized learning Revolution
Students are not just consumers of this technology. They are becoming its first generation of active users. Multimodal Generative AI is tearing down the one-size-fits-all model of education. It is replacing it with a hyper-adaptive, engaging system.
Creating Adaptive Educational Content
A traditional textbook is a single modality (text/images). An Multimodal Generative AI system can take that text and immediately create a corresponding video lecture, an interactive 3D simulation, and a Q&A audio session. This is the essence of personalized learning.
- Students who are visual learners receive video and image outputs.
- Auditory learners get comprehensive, generated audio summaries.
- Kinesthetic learners engage with interactive, generated simulations.
This dramatically enhances comprehension and retention. It makes previously inaccessible concepts clear. In this way, AI becomes a truly customized tutor for every student.
Accelerating Complex Research with Cross-Modal Search
Research often involves sifting through massive datasets of different types. A student researching a historical event might need to cross-reference archival text documents, historical photographs, and oral testimony (audio).
Multimodal Generative AI streamlines this. It allows a student to ask a question based on an image, and the AI responds with relevant passages from a text document. This form of cross-modal search accelerates the research process. It allows for deeper, faster insights than ever before. This is a core benefit of powerful AI models, as further discussed in our article .
Technical Deep Dive: Architectures for True Multimodality
Understanding the architectural foundations of Multimodal Generative AI is key for both technical professionals and discerning students. This is not simply about linking two separate models. It requires novel approaches to data processing.
Data Fusion Techniques (Early vs. Late Fusion)
The challenge lies in making different data types “speak the same language.” This is achieved through fusion, the process of combining modality features.
- Early Fusion: This combines the raw or basic features of each modality at the start. For example, text tokens and image pixels are merged early in the neural network. This method allows the AI to learn deep, subtle relationships.
- Late Fusion: This processes each modality separately using its own specialized encoder. The final outputs (e.g., text summary, image classification) are combined only at the final decision layer. This offers more flexibility but may miss deep cross-modal learning cues.
Most modern, high-performance Multimodal Generative AI models utilize a sophisticated form of intermediate fusion. They merge and re-merge features at various network depths. This technique maximizes contextual understanding.
The Role of Attention Mechanisms in cross-modal learning
The success of cross-modal learning is heavily dependent on attention mechanisms. These are the parts of the model that decide which pieces of information—from which modality—are most relevant to the current task.
For example, when generating a video caption, the AI’s attention mechanism focuses on specific objects in the image (vision modality) while simultaneously focusing on the relevant subject and verb in the prompt (text modality). This highly selective focus ensures that the output is both accurate and coherent across all modes. This powerful fusion technique is what makes the generated content so high-quality.
Practical Applications for Students and Working Professionals
The theoretical benefits translate into measurable, real-world productivity gains across sectors. This technology is no longer an academic pursuit. It is an essential tool.
Case Study 1: creative automation in Marketing
A leading marketing agency needed to generate 100 localized banner ads and a corresponding 30-second video for a new product launch.
The use of Multimodal Generative AI for creative automation reduced the total campaign time from 7 weeks to less than 2 days. The AI handled the generation of the generative video, AI music creation, and image variants from a single core text brief. This demonstrates a phenomenal efficiency gain for working professionals. You can learn more about mastering these skills through our .
Case Study 2: Medical Diagnostics and Multimodal Data
In healthcare, a radiologist uses Multimodal Generative AI to assist with diagnosis. The AI is fed the following:
- Image: An MRI scan of a patient’s knee.
- Text: The patient’s medical history and current symptoms.
- Audio: The doctor’s dictated summary of the consultation.
The AI fuses all three (image, text, audio). It then highlights potential pathologies in the image, cross-references them with the patient’s written history, and generates a structured report suggesting differential diagnoses. This enhances accuracy and speed. It significantly improves patient outcomes. This is a critical example of how fusion benefits both the professional and the end-user.We encourage further exploration of this field at the , a leader in applying AI to complex scientific problems here
Challenges and the Future of Multimodal Generative AI
As with any revolutionary technology, the road ahead is not without obstacles. Students and professionals alike must be aware of the technical and ethical challenges accompanying this rapid development.
Ethical Considerations in generative video Synthesis
The ability to create hyper-realistic generative video content raises major ethical concerns. Deepfakes, misinformation, and intellectual property theft are significant risks.
- The industry must prioritize robust watermarking techniques.
- Furthermore, strong detection methods are crucial.
- The ethical use of generated content is a core competency for the next generation of professionals.
The Road to Artificial General Intelligence (AGI)
Multimodal Generative AI is widely considered a major stepping stone toward Artificial General Intelligence (AGI). AGI is an AI that can understand, learn, and apply its intelligence to solve any problem a human can.
By bridging the gap between different senses (modalities), AI systems are developing a more human-like, comprehensive understanding of the world. The continuous integration of more data types—like haptic feedback, scent, and temperature—will drive this research. This field is constantly innovating, and platforms like Openai.com, Deepmind.com are integrating these advanced models into creative cloud tools, ensuring professionals stay on the cutting edge.
The Revolutionary Future of Multimodal Generative AI is here. It demands a new set of skills: creative prompting, ethical curation, and cross-modal thinking. The time for students and professionals to adapt is now.





